quickstart
helloword
wc
1.新建maven项目
2.编写pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.matt</groupId>
<artifactId>stu-flink</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!-- flink 使用到scala 组件-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--打包工具-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
3.编写日志配置文件
log4j.properties
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
运行时参数指定

4.具体代码

部署
mac-Standalone 模式
修改文件所有者
# 查看当前用户
whoami
# 查看用户组
id matt
# 用户名:组名
chown -R matt:staff /opt/software
chown -R matt:staff /opt/module
查看更多用户相关信息
https://blog.csdn.net/qq_26129413/article/details/109675386
下载解压
配置
修改 flink/conf/flink-conf.yaml 文件 jobmanager
如果是单机安装默认即可,集群安装配置某台主机
修改 /conf/workers 文件 taskmanager
从机机器列表
如果是集群安装可以配置为
如果是集群安装需要把flink同步到其他机器
其他配置
- jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
- taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
- taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的Slot数量进行配置,默认为 1,可根据 TaskManager 所在的机器能够供给 Flink 的 CPU 数量决定。所谓Slot 就是 TaskManager 中具体运行一个任务所分配的计算资源。
- parallelism.default:Flink任务执行的默认并行度,优先级低于代码中进行的并行度配置和任务提交交时使用参数指定的并行度数量。
启动
在jobmanger机器上进行启动
bin
提交任务
依赖的jar 包也打进去
<build>
<plugins>
<!--打包工具-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
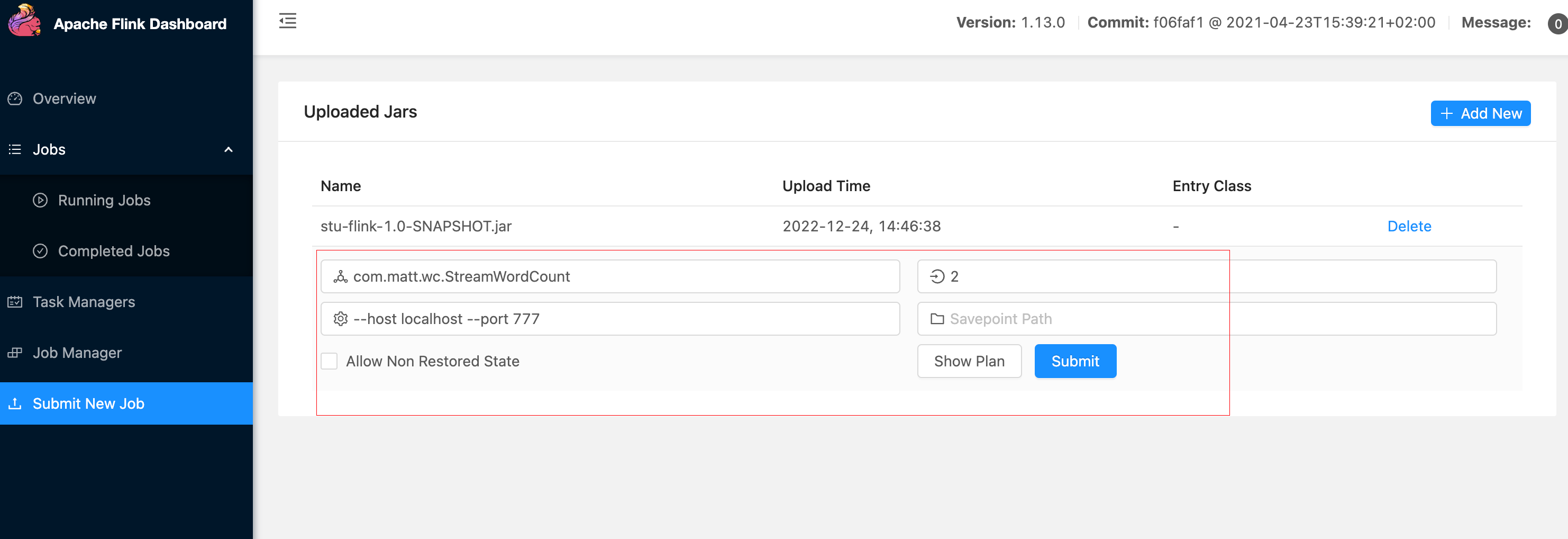
ui 提交
http://localhost:8081/#/overview

❯ ./bin/flink list
Waiting for response...
------------------ Running/Restarting Jobs -------------------
24.12.2022 15:11:40 : a21e498f6c313c5be5941d45aaef4ed1 : Flink Streaming Job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
❯ ./bin/flink cancel a21e498f6c313c5be5941d45aaef4ed1
Cancelling job a21e498f6c313c5be5941d45aaef4ed1.
Cancelled job a21e498f6c313c5be5941d45aaef4ed1.
命令行提交
可以通过命令行提交也可以ui进行提交
-m ip
./bin/flink run -c com.matt.wc.StreamWordCount -p 1 stu-flink-1.0-SNAPSHOT.jar --host localhost --port 777
部署模式
会话模式
启动一个flink集群 ,提交作业, 所有作业公用一个集群
单作业模式
由客户端运行 应用程序,然后启动集群,作业被交给 JobManager,进而分发给 TaskManager 执行。作业完成后,集群就会关闭,所有资源也会释放。
Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如 YARN、Kubernetes。
1.15 已被抛弃
应用模式
不需要客户端,直接把应用提交到 JobManger 上运行我们需要为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了。
会包含多个作业
独立模式部署
会话模式
先启动集群会提交作业
单作业模式
Flink 本身无法直接以单作业方式启动集群,一般需要借助一些资 源管理平台。所以 Flink 的独立(Standalone)集群并不支持单作业模式部署。
应用模式部署
应用模式下不会提前创建集群,所以不能调用 start-cluster.sh 脚本。我们可以使用同样在 bin 目录下的 standalone-job.sh 来创建一个 JobManager。
具体步骤如下:
(1)进入到 Flink 的安装路径下,将应用程序的 jar 包放到 lib/目录下。
(2)执行以下命令,启动 JobManager。
这里我们直接指定作业入口类,脚本会到 lib 目录扫所有的 jar 包。
(3)同样是使用 bin 目录下的脚本,启动 TaskManager。
(4)如果希望停掉集群,同样可以使用脚本,命令如下。
TODO yarn/k8s部署
运行架构

构成
JobManager
JobManager 是一个 Flink 集群中任务管理和调度的核心,是控制应用执行的主进程。每个应用都应该被唯一的 JobManager 所控制执行。当然,在高可用(HA)的场景下可能会出现多个 JobManager;这时只有一个是正在运行的领导节点(leader),其他都是备用节点(standby)。
JobMaster
在作业提交时,JobMaster 会先接收到要执行的应用。这里所说“应用”一般是客户端提交 交来的,包括:Jar 包,数据流图(dataflow graph),和作业图(JobGraph)。
JobMaster 会把 JobGraph 转换成一个物理层面的数据流图,这个图被叫作“执行图” (ExecutionGraph),它包含了所有可以并发执行的任务。JobMaster 会向资源管理器 (ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 TaskManager 上。
而在运行过程中,JobMaster 会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
资源管理器(ResourceManager)
主要负责资源的分配和管理。在 Flink 集群中只有一个。所谓“资源”, 主要是指 TaskManager 的任务槽(task slots)。任务槽就是 Flink 集群中的资源调配单元,包含 了机器用来执行计算的一组 CPU 和内存资源。每一个任务(Task)都需要分配到一个 slot 上 执行。
Flink 的 ResourceManager,针对不同的环境和资源管理平台(比如 Standalone 部署,或者 YARN),有不同的具体实现。在 Standalone 部署时,因为 TaskManager 是单独启动的(没有 Per-Job 模式),所以 ResourceManager 只能分发可用 TaskManager 的任务槽,不能单独启动新 TaskManager。
而在有资源管理平台时,就不受此限制。当新的作业申请资源时,ResourceManager 会将 有空闲槽位的 TaskManager 分配给 JobMaster。如果 ResourceManager 没有足够的任务槽,它 还可以向资源提供平台发起会话,请求提供启动 TaskManager 进程的容器。另外, ResourceManager 还负责停掉空闲的 TaskManager,释放计算资源。
Dispatcher
主要负责提供一个 REST 接口,用来提交应用,并且负责为每一个新提交的作 业启动一个新的 JobMaster 组件。Dispatcher 也会启动一个 Web UI,用来方便地展示和监控作业执行的信息。Dispatcher 在架构中并不是必需的,在不同的部署模式下可能会被忽略掉。
TaskManager
TaskManager 是 Flink 中的工作进程,数据流的具体计算就是它来做的,所以也被称为 “Worker”。Flink 集群中必须至少有一个 TaskManager;
当然由于分布式计算的考虑,通常会 有多个 TaskManager 运行,每一个 TaskManager 都包含了一定数量的任务槽(task slots)。Slot
是资源调度的最小单位,slot 的数量限制了 TaskManager 能够并行处理的任务数量。 启动之后,TaskManager 会向资源管理器注册它的 slots;收到资源管理器的指令后, TaskManager就会将一个或者多个槽位提供给JobMaster调用,JobMaster就可以分配任务来执行了。
在执行过程中,TaskManager 可以缓冲数据,还可以跟其他运行同一应用的 TaskManager交换数据。
任务提交流程
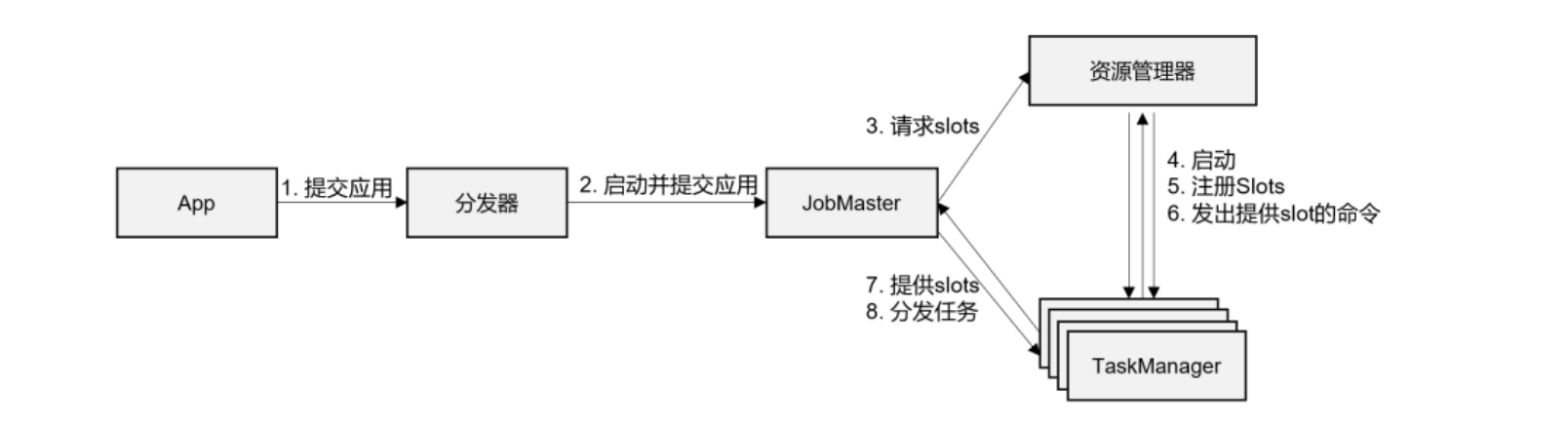
抽象
- 一般情况下,由客户端(App)通过分发器提供的 REST 接口,将作业提交给JobManager。
- 由分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
- JobMaster 将 JobGraph 解析为可执行的 ExecutionGraph,得到所需的资源数量,然后向资源管理器请求资源(slots)。
- 资源管理器判断当前是否由足够的可用资源;如果没有,启动新的 TaskManager。
- TaskManager 启动之后,向 ResourceManager 注册自己的可用任务槽(slots)。
- 资源管理器通知 TaskManager 为新的作业提供 slots。
- TaskManager 连接到对应的 JobMaster,提供 slots。
- JobMaster 将需要执行的任务分发给 TaskManager。
- TaskManager 执行任务,互相之间可以交换数据
部署模式不同,有些步骤可能不相同
独立模式
会话模式和应用模式 俩者是相似的
不会启动 TaskManager,而且直接向已有的 TaskManager 要求资源
yarn 集群
会话模式


在会话模式下,我们需要先启动一个 YARN session,这个会话会创建一个 Flink 集群。
这里只启动了 JobManager,而 TaskManager 可以根据需要动态地启动。在 JobManager 内部,由于还没有提交作业,所以只有 ResourceManager 和 Dispatcher 在运行
- 客户端通过 REST 接口,将作业提交给分发器。
- 分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
- JobMaster 向资源管理器请求资源(slots)。
- 资源管理器向 YARN 的资源管理器请求 container 资源。
- YARN 启动新的 TaskManager 容器。
- TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
- 资源管理器通知 TaskManager 为新的作业提供 slots。
- TaskManager 连接到对应的 JobMaster,提供 slots。
- JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
单作业模式
- 客户端将作业提交给 YARN 的资源管理器,这一步中会同时将 Flink 的 Jar 包和配置 上传到 HDFS,以便后续启动 Flink 相关组件的容器。
- YARN的资源管理器分配Container资源,启动Flink JobManager,并将作业提交给 JobMaster。这里省略了 Dispatcher 组件。
- JobMaster 向资源管理器请求资源(slots)。
- 资源管理器向 YARN 的资源管理器请求 container 资源。
- YARN 启动新的 TaskManager 容器。
- TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
- 资源管理器通知 TaskManager 为新的作业提供 slots。
- TaskManager 连接到对应的 JobMaster,提供 slots。
- JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,区别只在于 JobManager 的启动方式,以及省去了分发器。当第 2 步作业提交交给 JobMaster,之后的流程就与会话模式完全一样了。
应用模式
应用模式与单作业模式的提交流程非常相似,只是初始提交给 YARN 资源管理器的不再是具体的作业,而是整个应用。一个应用中可能包含了多个作业,这些作业都将在 Flink 集群中启动各自对应的 JobMaster。
一些重要概念
数据流图(Dataflow Graph)
所有的 Flink 程序都可以归纳为由三部分构成:Source、Transformation 和 Sink。
- Source表示“源算子”,负责读取数据源。
- Transformation表示“转换算子”,利用各种算子进行处理加工。
- Sink表示“下沉算子”,负责数据的输出。
在运行时,Flink 程序会被映射成所有算子按照逻辑顺序连接在一起的一张图,这被称为 “逻辑数据流”(logical dataflow),或者叫“数据流图”(dataflow graph)。
并行度(Parallelism)
并行计算
一条数据正在执行flatMap 之前的数据可能正在执行读取
多条数据同时来,可以在不同节点同时计算
并行子任务和并行度
每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)
并行度设置
代码设置
提交任务设置
配置文件设置 flink-conf.yaml
算子链 Operator Chain
算子链传输
1:1 source,map
重分区
keyBy,window,sink
在 Flink 中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个 “大”的任务(task),这样原来的算子就成为了真正任务里的一部分这样的技术被称为“算子链”(Operator Chain)。
// 禁用算子链
.map(word -> Tuple2.of(word, 1L)).disableChaining(); // 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()
作业图与执行图
逻辑流图
这是根据用户通过 DataStream API 编写的代码生成的最初的 DAG 图,用来表示程序的拓 扑结构。这一步一般在客户端完成。
源算子 Source(socketTextStream())→扁平映射算子 Flat Map(flatMap()) →分组聚合算子 Keyed Aggregation(keyBy/sum()) →输出算子 Sink(print())。
作业图(JobGraph)
将多个符合条件的节点链接在一起 合并成一个任务节点,形成算子链,这样可以减少数据交换的消耗。
执行图(ExecutionGraph)
JobMaster 收到 JobGraph 后,会根据它来生成执行图(ExecutionGraph)。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。
物理图(Physical Graph)
JobMaster 生成执行图后, 会将它分发给 TaskManager;各个 TaskManager 会根据执行图 部署任务,最终的物理执行过程也会形成一张“图”,一般就叫作物理图(Physical Graph)。
任务(Tasks)和任务槽(Task Slots)
slot 目前仅仅用来隔离内存,不会涉及 CPU 的隔离
只要属于同一个作业,那么对于不同任务节点的并行子任务,就可以放到同一个 slot 上执行。